Alfred Workflow で unixtime を日付に変換するスクリプトをつくる
はじめに
周りの人が使っているのを見て良さそうだったので、最近メジャーバージョンが 4 から 5 に上がったのを機に alfred の有料版を買いました。
有料版の機能の一つに workflow というキー入力に対して何らかの内部処理と出力を対応させるというものがあります。例えば"aws s3"と入力したら web の s3 の URL にとべたり、"emoji cool"と入れたら cool っぽい絵文字を clipboard に出力することができます。 awesome な workflow をまとめているサイトにいろいろ載っています。
workflow はありものを使うだけでなく自作も可能なので、簡単なものを作成してみることにしました。
作成したもの
unixtime を日付に変換するものと、その逆変換を行うものを作成しました。


手順
1. alfred の gui で入出力のブロックを置く
 こんな感じで入力に Script Filter、出力に Copy to Clipboard を置きます。
unixtime ⇨ 日時 とその逆変換で 2 つ Script Filter を置いています。出力はクリップボードへのコピーで共通なので1つです。
こんな感じで入力に Script Filter、出力に Copy to Clipboard を置きます。
unixtime ⇨ 日時 とその逆変換で 2 つ Script Filter を置いています。出力はクリップボードへのコピーで共通なので1つです。
2. スクリプトを記述する
Script Filter で読み込む用のスクリプトを作成します。 今回は Rust で書いてますが Python とかでも書けるはず。
unixtime ⇨ 日時
use chrono::{DateTime, Local, TimeZone}; use std::io; fn main() { let args: Vec<String> = std::env::args().skip(1).collect(); let unixtime = args[0].parse::<i64>().unwrap(); let dt: DateTime<Local> = Local.timestamp(unixtime, 0); let _ = alfred::json::write_items( io::stdout(), &[alfred::ItemBuilder::new(dt.to_string()) .arg(dt.to_string()) .subtitle("convert unixtime to datetime") //.icon_filetype("public.folder") .into_item()], ); }
日時 ⇨ datetime
use chrono::{DateTime, Local, TimeZone}; use std::io; fn main() { let input_args: Vec<String> = std::env::args().skip(1).collect(); let input_args_str: String = input_args.get(0).unwrap().to_string(); let args: Vec<&str> = input_args_str.split_whitespace().collect(); let yyyymmdd = args[0]; let mut hms = ""; if args.len() == 1 { //日時を指定しないケース hms = "00:00:00"; } else { hms = args.get(1).unwrap(); } let dt: DateTime<Local> = Local .datetime_from_str(&(yyyymmdd.to_string() + hms), "%Y%m%d %H:%M:%S") .unwrap(); let timestamp: i64 = dt.timestamp(); let _ = alfred::json::write_items( io::stdout(), &[alfred::ItemBuilder::new(timestamp.to_string()) .arg(timestamp.to_string()) .subtitle("convert datetime to unixtime") //.icon_filetype("public.folder") .into_item()], ); }
例外処理とか入れてないので invalid な入力に対しては出力が出ませんが、自分用なのでいいでしょう。
入力は普通に標準入力として受け取れますが、複数の引数を入力したい場合は注意が必要です。 alfred における引数の入力では複数の引数があってもそれを一つにまとめてしまうらしく、 例えば引数が 20200910 00:00:00 という場合、arg[0]に 20200910、arg[1]に 00:00:00 が入ってきて欲しいのですが、args[0]にすべての引数が入ってきます。そのため上記のコードでは args[0] の中をさらに parse するという処理を行なっています。
出力部分は alfred 特有の json 形式にする必要がありますが、 Rust だとcrate があるのでこれを利用して記述します。
3. 作成したスクリプトを alfred から読み込めるよう設定する

worlflow のフォルダを上記の処理で開き、Rustでコンパイル済みの実行ファイルをこのフォルダにコピーします。
次に、Script Filterの設定画面を開き、実行ファイルの名前をコピーしたもの(この例では u2d)に置き換えれば完了です。

メモ
alfred はまだ初心者であまり機能を使いこなせている気はしませんが、 このようなよくやるけど何ステップか処理が必要なことを簡易化できるので、何か面白い使い道ができたらなーと思います。
参考資料
kindleの積読本をランダムでslackに通知する
はじめに
kindleで購入した本が増えてきました。セール時にまとめて購入するケースが多く、必然的に購入したが読んでいない本も増えてきます。 kindleでは表示が購入が新しいものから順に並ぶため、積読期間が長くなるとリストの後方に移動していき、その存在を忘れてしまうことがあります。時にはリストの奥底に埋没した彼らの存在を思い返すことも必要なのではないでしょうか?
このあたりの記事の発想に近いですね。
実施したこと
1. kindle購入リストを取得
この記事の手順をそのまま使わせていただきました。 zenn.dev
kindleのPC用アプリをインストールしてログインすると、ローカルにkindleの蔵書リストを含むxmlファイルが作成されます。
私のM1mac環境だと以下にファイルが作成されました。
~/Library/Application Support/Kindle/Cache/KindleSyncMetadataCache.xml
あとはこのxmlファイルをパースすれば以下のようにcsv形式の書籍のリストができます。 (パースのコードも参考記事に記載されています。)

2. リストに既読フラグを手動付与
残念ながら、xmlファイルの中には未既読のフラグは入っていません。 幸いにして書籍のリストは1000に満たないくらいしかなかったので、既読フラグを手動付与します。 ついでに分析用途で使用するために書籍のジャンル情報も付与します。
付与後のデータはこんな感じ(genre列とread列が手動付与対象)

3. GAS(Google App Script)でリストを読み取り未読本をランダムでslackに通知
2で作成したリストを元に、未読本をランダムで定期的にslackに通知する仕組みを作ります。 実現する方法はいろいろありますが、今回はGASでスクリプトを定期実行するやり方をします。 Javascriptを少し書く必要がありますが、サーバを用意する必要がないのがメリットですね。
こちらの記事を参考に作成させていただきました。
参考記事との差分はコード部分なので、その部分だけ記述していきます。
まずspreadsheetにアップロードされたリストの読み込みを行い、最終行を取得します。
function post_thundoku() {
const spreadsheet = SpreadsheetApp.openById('{spreadsheetのIDを入力}')
const sheet = spreadsheet.getSheetByName('kindle蔵書_211225v2')
const lastRow = sheet.getDataRange().getLastRow()
次に、未読の行番号のリストを作成し、その中からランダムで1つ行を選択します。 選択後、その行のASIN,title,author,publisherの情報を取得します。
valid_rows = [];
for (var i = 2; i <= lastRow; i++) {
if (sheet.getRange(i, 11).getValue() === 0){
valid_rows.push(i)
}
}
select_row = valid_rows[Math.floor(Math.random() * valid_rows.length)];
ASIN = sheet.getRange(select_row, 1).getValue()
title = sheet.getRange(select_row, 2).getValue()
author = sheet.getRange(select_row, 3).getValue()
publisher = sheet.getRange(select_row, 4).getValue()
最後に取得した情報を整理してslackにメッセージを投げます。
const SLACK_WEBHOOK_URL = 'https://hooks.slack.com/services/XXXXXXXXXXXXX'
msg = "積読本をお知らせします。 \n 書名:" + title + "\n" + "著者:" + author + "\n" + "出版社:" + publisher + "\n" + 'https://www.amazon.co.jp/dp/' + ASIN
const jsonData = {
"text": msg,
"unfurl_links": true
}
const payload = JSON.stringify(jsonData)
const options = {
"method": "post",
"contentType": "application/json; charset=utf-8",
"payload": payload
}
UrlFetchApp.fetch(SLACK_WEBHOOK_URL, options)
}
上記のスクリプトを実行するとこんな感じでslackに積読本が通知されるものができました。

GASでスクリプトを実行する周期は設定できますが、とりあえず1日に1回動作するようにしています。
まとめ
kindleの未読本を定期的にslackに通知する仕組みを作成しました。 これで埋没した積読本にも日の当たる機会が生まれやすくなるのではないでしょうか。
あと改善点としては運用フローがちょっと面倒というのがあって、 新しい本を購入したときや、ある本を既読にしたときに手動で元リストを更新する必要があるのでそのあたりもう少しなんとかならないかなという思いがあります。
Atcoder Heuristic Contestの順位とアルゴリズムのレートの関係性を眺める
はじめに
Atcoder Heuristic Contest(AHC)は最適解を出すのが難しい問題に対し、出来るだけ良い解を作成するコンテストで、 開催期間が1週間以上の長期コンテストと、1日未満の短期コンテストがあります。
ABC/ARC/AGCのような最適解を求めるアルゴリズムコンテストとは性質の異なるものにはなるのですが、 体感としてアルゴのレーティングが相対的に低い人は長期コンテストの方が良い順位がとりやすい感じがしたので、 それをデータを見て確認したいと思います。
必要なデータはAtCoderの順位表のページのURLに/jsonをつければjson形式で取得できるので、それを利用しています。
コンテスト種別
現在まででRatedのヒューリスティックコンテストは9回開催されており、 うち5回が短期、4回が長期コンテストでした。
| コンテスト名 | 開催期間 | 種別 |
|---|---|---|
| AtCoder Heuristic Contest 001 | 9日 | 長期 |
| AtCoder Heuristic Contest 002 | 4時間 | 短期 |
| AtCoder Heuristic Contest 003 | 9日 | 長期 |
| AtCoder Heuristic Contest 004 | 6時間 | 短期 |
| AtCoder Heuristic Contest 005 | 4時間 | 短期 |
| RECRUIT 日本橋ハーフマラソン 2021〜増刊号〜 | 8日 | 長期 |
| HACK TO THE FUTURE 2022 予選 | 11日 | 長期 |
| AtCoder Heuristic Contest 006 | 4時間 | 短期 |
| AtCoder Heuristic Contest 007 | 4時間 | 短期 |
データの確認
各コンテストの、順位とアルゴリズムのレーティングとの散布図が下記になります。 順位が縦軸、レーティングが横軸です。 参加回数が少ない場合は実力との乖離が出るため、今回アルゴリズムコンテストの参加回数が20回未満の人はデータから除外しています。

どれもゆるい逆相関になります。若干ですが長期コンテストの方がばらつきが大きいように見えます。 各コンテストの相関係数は以下のようになりました。
| contest | 相関係数 |
|---|---|
| ahc001 | -0.45 |
| ahc002 | -0.52 |
| ahc003 | -0.44 |
| ahc004 | -0.54 |
| ahc005 | -0.63 |
| recruit | -0.44 |
| httf | -0.40 |
| ahc006 | -0.56 |
| ahc007 | -0.63 |
短期コンテストの相関は-0.4~-0.45、長期コンテストの相関は-0.52~-0.63なので、 全体の傾向としては、短期コンテストの方がアルゴのレートとの相関が低くなるようです。
次に、上位に入る人の傾向も変わるのかを確認するため、 各コンテストで100位以内に入った人のアルゴレートの色別比率を示します。

100位以内に限定してみるとそれほど長期と短期で違いが現れないようです。
より絞って30位以内の色別比率を見てみます。

30位以内に絞ると長期と短期で傾向に違いが出てきます。 特に青色以下の人が30位以内に入る比率が短期だと平均20%程度なのに対し、長期だと50%近くまで増加します。
まとめと考察
- 長期コンテストの方が短期コンテストよりもアルゴの能力の影響は小さい。
- アルゴのレートが相対的に低い人が上位(30位程度)を目指す場合、長期コンテストの方が優位になりやすい
という結果でした。このようになる理由としては、
- 長期コンテストではコンテストに使える時間が人によって異なる
- 長期コンテストの方が問題構造が複雑でアルゴと異なる能力が要求される
の2点が考えられそうかな思っています。 使える時間が異なる場合は時間をつぎ込んだ人の方が順位は高くなりやすいので、ばらつきが大きくなるのはそうだろうなーというのが1つと、 例えば長期コンテストのahc003やhttfではパラメータ推定をする必要があったのですが、こういった問題への対処はアルゴリズムとはまた別分野の知識が必要になりそうなので、アルゴレートとの関係性が低くなるのかなと思っています。
使用したコードは以下になります。
HACK TO THE FUTURE 2022 予選 参加記
結果としてはシステムテスト前で94890点で、100位ちょうどの順位でした。
問題
解法
問題を以下の3つに要素に分解して考えました。
タスクに依存関係があるので、重要度をつける
メンバの技能レベル推定を行う
各タスクに対し、適切なメンバを割り当てる
1. タスクの実行優先度付け
タスクに依存関係があるので、依存関係の多いタスクを早めに実施しないとタスク詰まりがおきます。 クリティカルパスを探すという作業に近い気がします。 最終的には依存関係にあるタスクの中で足し上げた合計技能レベルが最大となる値をタスクの重要度とおき、重要度順にタスクを実行するようにしました。 括弧外がタスクid、括弧内がタスクの合計技能レベルとして、タスク1の重要度を求める以下の例だと合計技能レベルが最大となるパターンは3番目で、その値は45というようにしました。
1(5)→2(10)→3(20):計35
1(5)→2(10)→5(10)→6(10):計35
1(5)→4(30)→5(10):計45
他にも下記のようなことを試しましたが↑が一番スコアが良くなりました。
依存関係にあるタスクの最大ホップ数
依存関係にあるタスクの合計数
依存関係にあるタスクの合計数*合計技能レベル
2. スキル推定
タスクの実行結果の履歴をすべて保存し、タスクが40個終わる毎に全メンバの技能レベルを更新します。 更新頻度は実行時間制限にあわせて調整しています(このへんpythonによる不利はどれくらいあるんだろう?)。 更新方法は技能スキルをランダムに増減させて、実際値の誤差が小さくなったら更新するという焼きなましです。 山登りで良いような気がしたのですが、少し戻り要素を入れた方がスコアは上がりました。
推定方法を考えるにあたってAHC003の解法を参考にしてもう少し解析的な方法を取りたかったのですが、maxが入っている式の扱いをどうしたらよいかわかりませんでした…。
3. 各タスクに対し、適切なメンバを割り当てる
最初この部分を全く行わず、来た順に処理するという形にしてタスク順調整をしていたのですが、スコアが初期貪欲解から全く向上しませんでした。 クリティカルパスがわかっていても、そのパスに適切に技能レベルの高い人を当てられないと意味がないという問題設定みたいでした。
ここのロジックは手が空いている人の中で最もタスク処理時間が早い人を割り当てるようにしました。 また、途中で手が空いていても実行にかかる時間が最速で処理できる人に対して一定以上かかる人に対してはタスクを割り当てないという仕組みを入れたらスコアが伸びました。
その他
- 3の部分はもう少し良い方法がありそうと思いつつ貪欲でしか考えられなかった。
- スコアは手元でseed0~49の50回分の合計で評価していた。ただ提出時との乖離が4000点くらいあり不安だったので、終盤は1000ケース回した値を利用していた。(ただし1000ケース回すのには1時間弱かかっていたが…)
- コードの整理をあまりしなかったせいで最後の方高速化しようとしたときにかなりバグらせた。
- アイデアの多くはビジュアライザを見ていて思いついたものだったので、可視化は大切
SIRモデルとネットワークモデルを用いて身近にコロナ感染経験者が存在する確率をシミュレーションする
はじめに
最近は街を見ると人通りがコロナ前に戻っていたりしますが、感染者数自体はそれほど減っていないのでこのような状況となっているのは、身近にコロナの感染経験者がいないことも原因の一つであるのではないかという仮説があります。人は身近に起こったことや直近で起こったことを過大評価する反面、逆のケースには鈍感であるという傾向があります。そのため身近に感染経験者がいない場合、報道や注意喚起に従う可能性が低下する可能性があるのではないかと考えています。
人と人とのつながりは仕事やサークル、地域等の集団があり、それらの集団同士がゆるく繋がっているという性質があります。そのため、感染経験者のいる集団には感染者は多くいるが、そうでない集団では感染経験者が全くいないという状況が発生し、後者の集団では感染者数という数字以上にコロナを身近に感じる可能性が下がるのではないかと考えています。
今回はその検証のためSIRモデルとネットワークモデルを用いたシミュレーションモデルを作成します。
※注意事項:今回の結果は多くの仮説の上に成り立っており、またあまり妥当性の高いモデルをつくれたとはいえないので、結果はあくまで思考実験の一つとして捉えていただけると幸いです。
使用モデルについて
SIRモデルとネットワークモデルについてはwebで詳細なものが簡単に見つかるため、ここでは簡単な説明のみ記述します。 SIRモデル+ネットワーク分析の実施方法についてはこちらの記事を参考にさせていただきました。
SIRモデルについて
感染症のモデルとして有名なものですね。
S(susceptible):未感染者
I(susceptible):感染者
R(susceptible):治癒者および死亡者
というパラメータを設定し、全体(S+I+R)を一定として確率的にS→IおよびI→Rへの遷移が発生するというシンプルなモデルになります。
ネットワークモデルについて
人の社会ネットワークは複雑ネットワークの一種として考えられ、その特徴としては、 知り合い関係を順にたどっていけば比較的簡単に世界中の誰にでも行き着くというスモールワールド性と、 大多数の人は少数の知人しかいないが、一部の人は非常に多くの知人をもつというスケールフリー性があると言われています。
スモールワールドを仮定するモデル構造としては ワッツ・ストロガッツモデル(WSモデル)。 スケールフリー性を仮定するモデル構造としてはバラバシ・アルバートモデル(BAモデル)が挙げられます。
今回は上記2つのモデルにランダムモデルを加えた3つモデルを用いて実験を行います。
動作イメージ
水色のノードが未感染者、橙色が感染者、緑色が治癒者・死亡者とし、 感染率と治癒率を1、ノード数を10とした場合のシミュレーションのイメージを示します。
step0
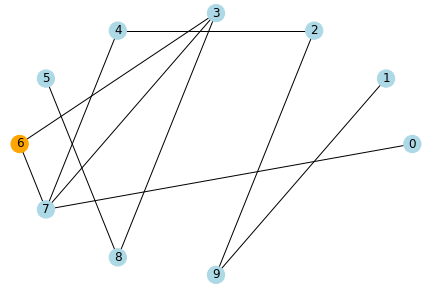
step1
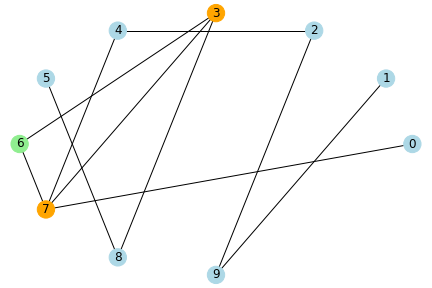
step2

step3
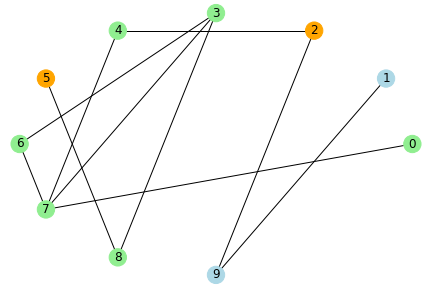
step4
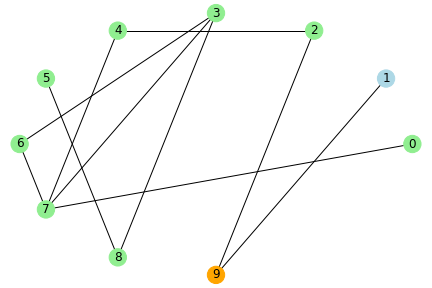
step5
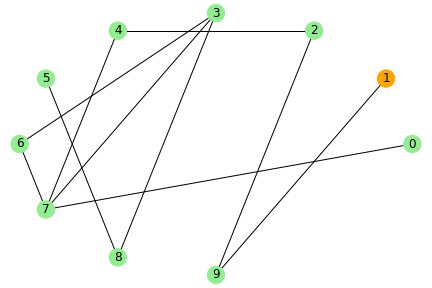
ネットワーク上でつながりのある人に感染が伝わっていき、このパラメータの場合だと、5stepで未感染者はいなくなりました。
実験
シミュレーションのパラメータを現実に近づけます。 本当は日本全国を対象にしてシミュレーションを行いたかったのですが、 計算負荷の問題のため、今回は東京都港区のみを対象として現実に近いモデルを作成することを目指します。
東京都のサイト によると、データの始まりである2020年3月31日時点の陽性判者は39人、2021年6月25日時点では陽性判定者は5633人です。これと港区の人口が24万であるという情報を用います。
モデルのパラメータについて
SIRモデルのパラメータとしては、
感染率:0.007、治癒・死亡率:1/14、初期感染者数:10人
としています。これはできるだけ長い時間をかけて感染者を5000に近づけようと調整したものになります。 (これ以上感染者数を下げると感染者が5000人に届きません。)
このモデルのシミュレーションで1日毎に判定をかけて5000人を超えたタイミングで打ち切り、24万人の対象者それぞれに対し最も近い感染経験者への近さを算出します。
ワッツ・ストロガッツモデルのパラメータとして、一人当たりで繋がりのある人数は20人としています。 また、バラバシ・アルバートモデルのパラメータとして、繋がりのある人数の最小値を6としています。
以下コードになります。
import numpy as np import pandas as pd import networkx as nx import matplotlib.pyplot as plt import ndlib.models.epidemics as ep import ndlib.models.ModelConfig as mc from bokeh.io import output_notebook, show from ndlib.viz.bokeh.DiffusionTrend import DiffusionTrend # ネットワークモデル設定 g = nx.watts_strogatz_graph(240000, 20, 0.1, seed=42) # g=nx.barabasi_albert_graph(240000,6,seed=42) # g = nx.watts_strogatz_graph(240000, 20, 1, seed=42) # random graph model = ep.SIRModel(g, seed=42) # SIRモデル設定 cfg = mc.Configuration() cfg.add_model_parameter('beta', 0.007) # 感染率 cfg.add_model_parameter('gamma', 1/14) # 回復率(2週間) cfg.add_model_parameter("fraction_infected", 10/240000) # 初期感染率 model.set_initial_status(cfg) # SIRシミュレーションを実行、治癒・死亡者が5000を超えたら終了 S_num = [] I_num = [] R_num = [] for i in range(1000): tmp_params = model.iteration() S_num.append(tmp_params["node_count"][0]) I_num.append(tmp_params["node_count"][1]) R_num.append(tmp_params["node_count"][2]) if tmp_params["node_count"][1]+tmp_params["node_count"][2] > 5000: break if i % 10 == 0: print(i) # 感染者および治癒・死亡者のノードリスト作成 inected = [] for i in range(len(model.status)): if model.status[i] > 0: inected.append(i) # 感染者を起点として各ノードへの経路長を計算(最大探索経路長2)。 # 全感染者で実行後の最小値が各ノードから感染者への最小経路長となる。 d = {} for i in range(240000): d[i] = 99 # 各ノードから感染者への最短経路長を集計 cnt = 0 for i in inected: tmp = nx.single_source_shortest_path_length(g, i, cutoff=2) # カットオフの距離まで探索 for k, v in tmp.items(): if d[k] > v: d[k] = v # カウント pd.Series(d.values()).value_counts()
結果はこのようになりました。
| 感染者との近さ | randomモデル | WSモデル | BAモデル |
|---|---|---|---|
| 0 | 5221 | 5056 | 5165 |
| 1 | 78096 | 25022 | 97448 |
| 2 | 156564 | 127952 | 136958 |
| それ以上 | 119 | 81970 | 429 |
感染者との近さ=0の人は感染者自身です。 感染者との近さ=1である身近な人が感染したことのある割合はBAモデル>randomモデル>WSモデルという結果になりました。 今回のBAモデルの構造を見てみると、1000人以上と繋がりのある人が10人以上おり、その人たちが感染を媒介してしまうような動きをしていたのでこのような結果となっているようでした。BAモデルについては少し現実と乖離のあるものになってしまったなと思います。 ランダムモデルとWSモデルを比較すると、WSモデルの方はランダムモデルと比べ、近さが1である人の割合が約1/3となっています。 なので、もし現実の社会構造が今回のようなWSモデルであった場合には、実際の数字よりも身近に感染経験者がいる確率は1/3程度になるといえるのではないでしょうか。
まとめ
SIRモデル+ネットワークモデルを用い、身近な人に感染経験者が存在する確率を算出するためのシミュレーションを行いました。 ネットワークモデルとしてWSモデルを用いた場合に、ランダムモデルと比較すると身近な人が感染経験者である割合は約1/3という結果になりました。 ただ、今回の実験では以下のような現実との乖離が考えられるので、より妥当性の高い結果を出したいのであれば考慮していく必要がありそうです。
- SIRモデルは何も対策を取らない場合にどうなるかを予測するモデルであり、実際の感染者数は予測した数値を元に対策をとった後の数値となるので、実際の陽性者数をSIRモデルで模擬するのは難しい
- 実際のネットワークモデルは集団性を持ち、かつ繋がりのある人数は個人差があるので、WSモデルとBAモデルを混合したような構造になるのではないか
使用したコードは下記になります。
読書記録(2021年4,5月)
スマホ脳
")
現代人はスマホ(主にSNS)に脳をハックされているということを科学的に説明している本。 facebook等のSNSはユーザに多く使ってもらうことで利益を出すモデルであり、そのために大量の資金とテクノロジーがユーザの使用されている。 幸福に関する本を読むと大抵SNSはやめましょうという話が出ますね。 (逆に地域分断型の狭いSNSを作ったら幸福度は上がったりしないだろうか?)
デジタル・ミニマリスト
")
上記のスマホ脳と内容は類似しているが、この本ではその内容を踏まえた上で、私たちはどうしていくべきか?ということまで書かれている。 スマホはデジタル・スロットマシンという例えは印象に残った。 端的にいうとスマホを触らない期間を設けてその時間でできることを新たにさがし、SNSは最低限必要なものだけ残しましょうという結論。
ストーリーとしての競争戦略

経営戦略をどう考えてつくるべきかという本で、内容も筋が通っていて面白かった。 こんな感じでこの会社はこういう構造でやっていきます、というストーリーがあると社員としても働きやすいなと思った。 例えばスタバのようにフランチャイズ形式ではなく直営店形式にするというような、部分的に見れば不合理だが全体で考えると合理性がでるようなキラーパスをつくるという部分は興味深く、確かにこれがあると他者の参入難度が格段に上がると感じた。 あと今は戦略が綺麗に描ける企業も最初からこの形であったわけではなく、試行錯誤や失敗を経てこの形になっているので、現実で戦略パスが繋がらない箇所が出てきたら適宜対応・修正していく力も必要なんだろうなと感じた。
申し訳ない、御社をつぶしたのは私です。

コンサルの失敗談の話。最近はDX、少し前はAIのように、有名なフレームワークやソリューションをただ導入するだけではうまくいかないよという例が書かれている。 おそらくビジネスは科学ではないということが失敗の根幹であり、例えば部署間の連携を強化するなど、銀の弾丸のようなものはないので現場の状況やちゃんと観察して障壁となるものを一つ一つ改善していくのが結果的に最も効果が出るらしい。 問題をコンサルに丸投げすればなんとかなる思っているクライアントサイド側にも問題があり、 コンサルを使うのであれば、単純に実行リソースが不足している場合や第三者の意見や介入が必要なケースにすべきということだった。
闇の自己啓発

読書会の体裁をとっており、お題となっている本やそれに関連する知識(主に哲学や人文)がない私には内容の理解が難しかった。 ハーモニーとかのSF系の話だけは理解できたが、その部分も少し技術の発展を楽観視しすぎているように感じた。
腸科学
")
腸にはマイクロバイオータと呼ばれる微生物が数多くおり、その微生物の状態によって腸だけではなく、精神も影響を受けるという内容。健康に関わる科学の話は外乱が多く効果検証が難しい印象があり、著者の風邪の季節以外は微生物を摂取するために土を触った手を洗わず食事をとるなどの例は少し行き過ぎでは?と思う点もあった。個人的な所感としては、人によって合う微生物が異なるので、食物繊維等、食べると健康に良いと呼ばれるものを探索的に試していくのが現実的かなと思った。
小説家になって億を稼ごう
")
小説家として億を稼いでいる著者による実践的な本。小説の書き方的な本は数多くあるが、この本で特徴的なのは、 出版社の担当との付き合い方や映画化時の契約交渉等、本が出来上がった後に具体的に稼ぐための仕組みをどう作るかということにページを割いている点である。例えば執筆者から見たら担当は一人だが、担当からすると執筆者は複数人いるため意識の齟齬が起こりやすいため、客観的な視点をもつべきという考えはこの分野に限らず必要だと思う。
かがみの孤城
")
")
自分が現代ヒューマンドラマ+若干のファンタジーというジャンルが好きなのもあるが、ここ10年ぐらいで読んだ小説で一番面白かった。 主人公達は中高生だが、ささいなことで大きく揺れ動く感情がとてもリアルに描かれており、それを取り巻く親や先生など大人の対応も現実的なもので、両者の視点で自己投影が可能となっている。それに加えて、序盤より孤城とは何でなぜ主人公らはここに集められたのか、という謎に対して伏線が多く張られており、それがだんだんと紐解かれていく後半は展開が気になって一気に読んでしまった。
深層学習の原理に迫る
深層学習は応用利用が進んでいるが、なぜうまくいくのかが証明されているわけではない。 本著はその理由を専門家でなくてもわかるよう、かなり短く簡潔にまとめられている。 この本で説明されるのは深層学習の一部ではあるが、個人的にはVGG16がなぜ16で、15や17ではなぜだめなのか?がわからずNNの理解を進めるのを後回しにしてしまったので、このように理論的な説明をしてくれるのはありがたい。")
なぜこの店で買ってしまうのか ショッピングの科学
")
顧客行動分析の専門家である著者の、現場視点でショッピングの特性を記した本。 20年近く前に書かれた本なのでその部分は割り引いて読む必要があるが、 実店舗に張り付いて長年顧客調査をして得られた知見は現在も不変であるものが多い。
最近は技術の発展によりカメラを用いた導線分析や決済時のユーザ属性の取得もある程度可能にはなってきているが、例えば本で紹介されていた下記の情報を数字だけから見つけるのは結構難しいと思うし、
- 入口近くにある広告や商品は無視されやすい
- 混んでいる経路にある商品は購入されづらい
見つけたとしてどう問題を解決するかも実店舗を見てないと考えづらいだろうなと思う。
人はなぜ物語を求めるのか
")
人は、個別の事象から一般論を帰納し、その一般論から演繹して原因・理由を把握する。 つまり、人は物語を求めるというよりも、人は物語を通してしか事象を理解することができないという方が正しいのかもしれない。 物語を構成するパーツが足りない場合は補完する動きが働くので、災害など偶発性が高いものに関しても、自分が何々したからだと因果を自動構成するし、 論理の飛躍が起こるケースもある。事象を物語に変換するための一般論は自身の信念のようなものが基準となるので、人によって事象の解釈は大きく異なるし、逆にそこさえ変化させることができれば事象に対する自身の受け取り方や反応を変えられる可能性もある。
シン・ニホン AI×データ時代における日本の再生と人材育成
これからのAI×データ時代における世の中の変化が行われていく中で、国としてどういった政策をとり、また教育をしていくかということをデータを元に提案されていて興味深かった。国語の教育は小説等の書き手の理解ではなく、文章を正しく読み取り課題を抽出するという方針にした方が良いという部分はその通りだと思ったし、ひと昔前と比べると必要とされる能力の移り変わりのスパンが短くなっており、より自分で考えるというメタスキルを伸ばすような方針にできたら良いんだろうなと思った。")
map-matchingでランニングのgpsデータを補正してみる
はじめに
ランニングをする際にアプリを使って距離やスピードを測っているのですが、全く同じコースを走った場合でもgpsの誤差によってあるときは9.6km、またあるときは10.1kmのように走行距離が大きく変わってしまうケースがあります。今回はmap matchingという方法を用いてgpsの誤差を補正することでこの誤差の改善し、正確な距離を取得できないかを試みます。
実施したこと
実施した手順は以下になります。
1. runkeeperよりgpsデータを取得
ランニングアプリよりgpsデータを取得します。 私はrunkeeper(無料版)というアプリを用いているので、下記の手順に従いファイルを抽出します。
得られたファイルはgpx形式で、アクティビティ毎にファイルが分割されています。 他のアプリを利用している場合にも、似たような処理で抽出できるのではないかと思います。
2. mapboxのapiを用いてmap matchingを実行、緯度経度を補正
map mathchingはgpsデータと道路情報を元にgpsデータの誤差を補正する方法で、カーナビ等に用いられているようです。
map matching のアルゴリズムは理解しきれていないのですが、下記のlyft社の記事を参照すると状態空間モデルやカルマンフィルタを用いたものなど複数の手法があるようです。
mapboxにはmap matchingを実施してくれるapiがあるので、今回はそれを下記に参考に実装します。
事前にmapboxへの登録とトークンの払い出しが必要です。 料金は21年5月現在100,000リクエストまで無料なので、遊びで使う分には無料で行えると思います。
実装はこんな感じ。
from gpx_converter import Converter from mapbox import MapMatcher import numpy as np from geopy.distance import geodesic gpxfile="./01-runkeeper-data-export-2021-05-04-084136/2021-04-18-122351.gpx" #gpxをdict形式に変換 dic = Converter(input_file=gpxfile).gpx_to_dictionary(latitude_key='latitude', longitude_key='longitude') latlon=[] for i,j in zip(dic["latitude"],dic["longitude"]): latlon.append([j,i]) #datetimeはjson型にできないためstrに変換 dic["time"]=[i.isoformat() for i in dic["time"]] service = MapMatcher(access_token="XXXX") #map matching api は一度に100件までしか処理できないため分割処理 corrected=[] dist=0 for i in range(len(latlon)//100+1): #apiの入力形式に合わせる line={} line["type"]="Feature" line["properties"]={"coordTimes":dic["time"][i*100:(i+1)*100]} line["geometry"]={"type": "LineString","coordinates":latlon[i*100:(i+1)*100]} response = service.match(line, profile='mapbox.walking') print(i,response) #結果を統合 for i in response.geojson()['features']: corrected.extend(i["properties"]["matchedPoints"]) dist+=i["properties"]["distance"]
correctedに補正後の緯度経度情報が入ります。
3. 評価
結果を地図上にプロットして補正の結果を確認します。
青色が元のデータ、赤色が補正後のデータです。
うまくいっているケース。誤差でぐねぐねしてしまっているものが、ちゃんと直線に補正されています。
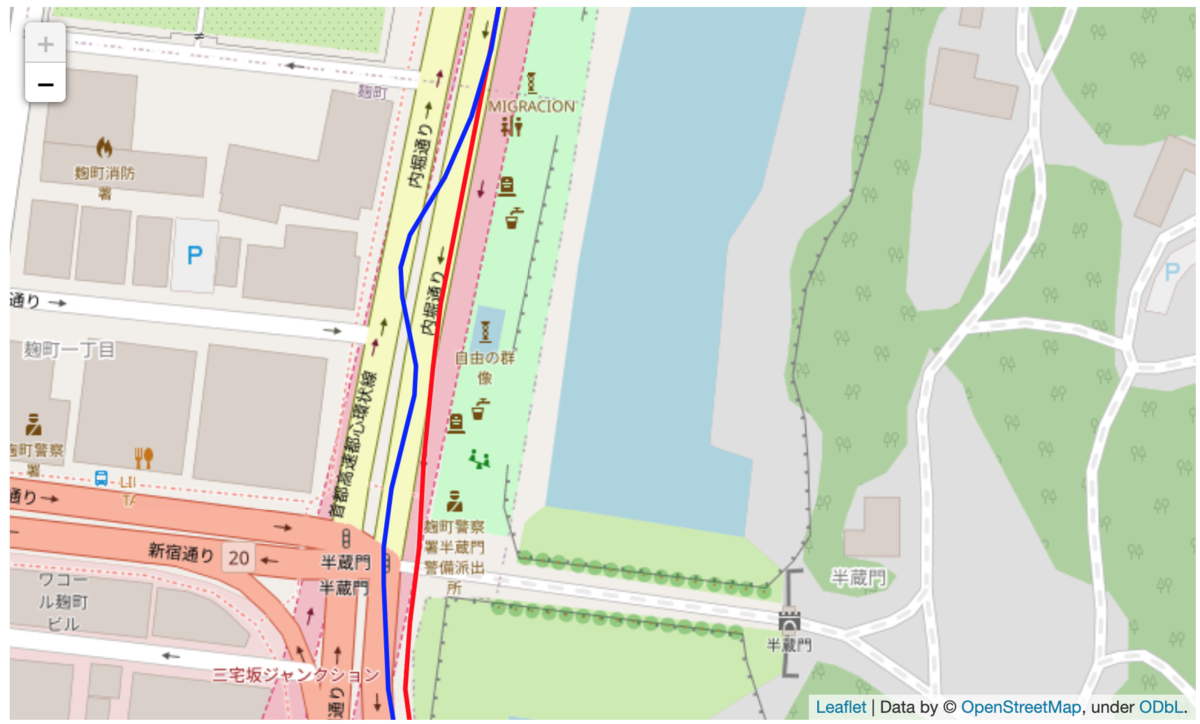
うまくいかなかったケース。往復で同じコースを走っているため線が二重になっています。 実際は常に大通りの右側を走っていますが、元のデータも補正後のデータも実態と乖離してしまっています。
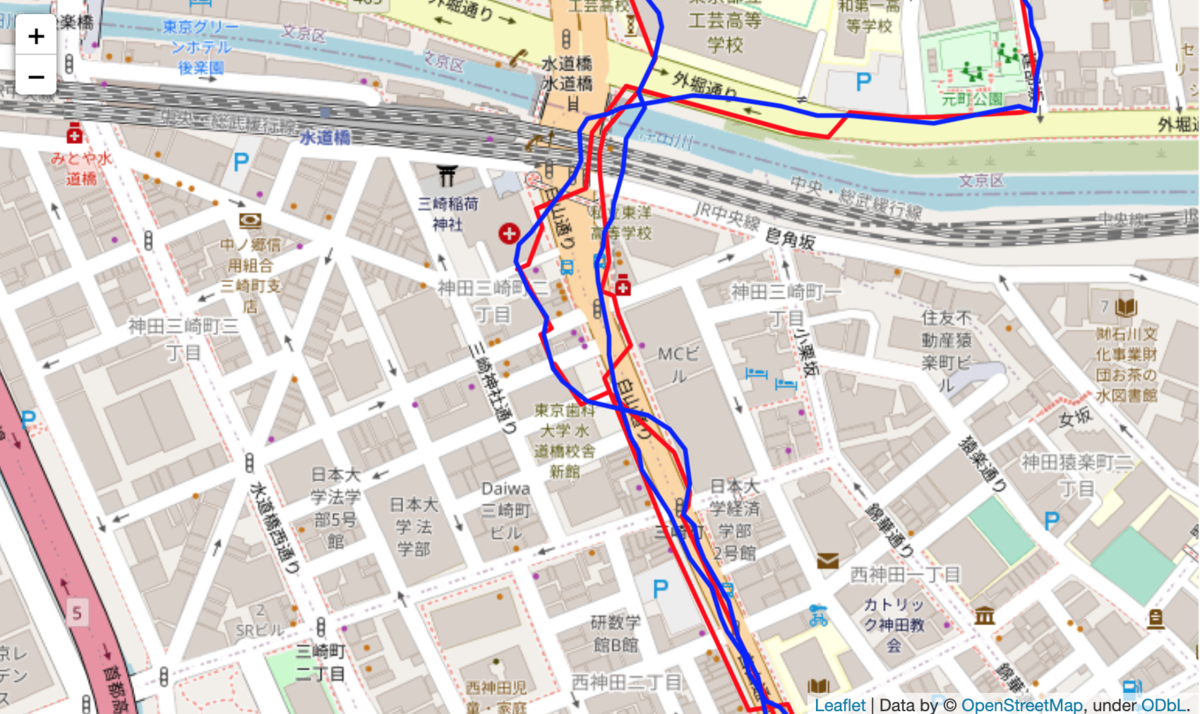
map mathingは基本的には取得地点の近くにある道路が選択されやすいと思うので、この方法では元のgpsデータに大きな乖離がある場合の補正は難しそうです。 また、このアプリでは基本的には3~4秒に1回gpsデータを取得しているのですが、中には数十秒データが取得できていない時間帯もありました。 1kmあたり6分のペースで走っていた場合、秒速換算すると2.77mなので、もし10秒間取得できない場所27.7m進むことになりますが、この間にカーブがあったりするとどうしてもショートカットするようなデータになってしまいます。 車に対してランニングは位置の自由度が高いので、それなりに誤差がでるのは仕方がないかなと思います。 (そもそもこれを正確に測りたいという需要があまりなさそう)
まとめ
ランニングアプリから抽出したgpsデータをmapboxのapiを用いてmap matchingし、誤差の補正ができるかを試みました。 結果としては確かに補正ができている部分もありますが、誤差が大きかったり、時間粒度が空いてしまっている場合など、そもそも補正が困難なgpsデータもそれなりに存在しているために、この補正によって正確な結果が出せるとは言えない結果になりました。 google mapで右クリック→距離の測定で手動でも距離が測れるので、ランニングの距離を正確に把握しておきたい場合はこちらを使用する方が良さそうです。
使用したコードは下記になります。
blog/gps_mapmatching_fix.ipynb at master · rmizuta3/blog · GitHub