読書記録(2021/2,3月)
ミクロ経済学の力

経済学は未履修だったので全体像を理解するのに役立った。 一つ一つの理論をより理解したくなったら別売りの演習本をやっていきたい。
誤解学
")
- 作者:西成 活裕
- 発売日: 2014/05/23
- メディア: 単行本
誤解の起きるパターンをモデル化して解釈している。 この本で紹介されているIMV分析だと
I:伝え手の真意 M:伝え手の発するメッセージ V:受けての解釈
として正直に伝わるケースだと
I=M=V=I
というようになるが、例えば伝え手が正直にメッセージを発することができず、受け手側で真意を推し量って正しく伝わるという
I≠M≠V=I
というケースもあるという話もあり、こういう構造化系の話は面白いなと思った。
意思決定分析と予測の活用
")
意思決定分析と予測の活用 基礎理論からPython実装まで (KS情報科学専門書)
- 作者:馬場 真哉
- 発売日: 2021/03/01
- メディア: 単行本
機械学習関連技術の進歩により予測精度はここ数年でだいぶ向上した印象があるが、 その予測値を実際どうやって意思決定などの価値につなげるか、という考え方が記載されている。 工学ではなく経済学に近しいイメージがある。 例えばある商品販売数の予測精度が10%向上したからといって売り上げが10%変わるわけではなく、 実際の廃棄ロス調整や店頭オペレーション最適化等のアクションにつなげて初めて効果が現れる。 その予測→アクションの部分の考え方の手法について豊富な分量で紹介されている。 例は単純なものであるのでそのまま使用できるというものではないと思うが、 価値をうまく定義し定式化するという基礎的な考え方が学べるのがいい点だと思った。
マーケターのように生きろ―「あなたが必要だ」と言われ続ける人の思考と行動

趣旨としては自分のやりたいことをやって他人の価値になることを生み出せるのはほんの一握りの人なので、 自分のやりたいことではなく、相手にとっての価値のあることを行う生き方を勧めている本。
個人の幸福度べースで考えた場合、以下のどっちが良いのだろうかという疑問は残る。
自分はやりたいが、あまり必要とされないこと
自分はそれほどやりたくないが、必要とされること
あとあまり情緒的な価値に重きを置きすぎると、何かをやって双方が満足するが、 事態は全く好転していないみたいなことも普通に起き得ると思うので、 個人的には1と2のバランスをいい塩梅でとるのがいいのだろうな、という感想。
統計外事態
")
タイトル買い。やたらと統計と猫という言葉が出てくるが内容は普通にSF。 「現状は完全に統計外事態だ」という言葉はどこかで言ってみたい。
最高の結果を出すKPIマネジメント

- KPIの設定には時間をかけて意味のあるものを作成する
- KPIの指標を元にサイクルを回せるようにする。
よく忘れる単語メモ
- KPI (Key Performance Indicator)
- KGI (Key Goal Indicator)
- CSF (Critical Success Factor)
統計分布を知れば世界が分かる
")
統計分布を知れば世界が分かる-身長・体重から格差問題まで (中公新書)
- 作者:松下 貢
- 発売日: 2019/10/16
- メディア: 新書
現実の事象を統計分布で説明している。 割と読みやすい。
絶望を希望に変える経済学
")
絶望を希望に変える経済学 社会の重大問題をどう解決するか (日本経済新聞出版)
- 作者:アビジット・V・バナジー,エステル・デュフロ
- 発売日: 2020/04/17
- メディア: Kindle版
移民、貿易、地球温暖化緩和のための二酸化酸素排出規制、ベーシックインカム等の問題について、経済学の観点で紹介している。
人の必ずしも合理的に行動するわけではなく、例えば引っ越すことによって収入が上がる期待値が大きい場合にもたいていは大きなきっかけが与えられない限り 現状の生活をつづけたり、申請すれば国からお金が受給できる場合でも、受給することで尊厳が失われてしまうことを忌避する場合もある。
そういった人間心理やバランスまで考えてモデル化→施策実行を行うのはかなり大変そうだなという印象。
一兆ドルコーチ

1兆ドルコーチ――シリコンバレーのレジェンド ビル・キャンベルの成功の教え
- 作者:エリック・シュミット,ジョナサン・ローゼンバーグ,アラン・イーグル
- 発売日: 2019/11/14
- メディア: Kindle版
思ったより情緒的な内容だった。チームとして成果を出すには、プライベートな部分も含めて信頼できるような関係性を構築する方がよいという話。 ビル氏の偉人伝みたいな側面もあるので理論的な裏付けも欲しい所だが、狩猟民族時代の特性みたいな話で説明がつくのかな。
書籍レビューを用いた潜在表現の獲得とクラスタリングの実施
はじめに
書籍に関連する情報を用いてその潜在表現をうまく獲得することで、 以下のようなことができないかなーと考えています。
- 自身の読書済みの本と照らし合わせて
- カテゴリごとの網羅率の算出
- 本を読んだ時に得られる情報量の算出
- 該当の本の完読可能性の推定
- 本を読むための事前知識の十分性確認
今回のスコープ
書籍に関する情報の1つであるレビュー情報を用いて潜在表現を作成し、 クラスタリングを行うことでその有効性の確認を行います。
潜在表現の作成は以下の2通りの方法で行いました。
1.TFIDF+LDA
2.Sentence-BERT
実施したこと
ブクログの2020年の登録者数の多い1000冊に対しレビューを取得、そこから30件以上レビューがある429冊に絞り30579件のレビューを元に書籍の潜在表現を生成しクラスタリングを行いました。
1.TFIDF+LDA
TFIDFで単語の出現頻度を元にしたベクトルを作成し、ある程度同じ意味の単語のトピックがまとまることを期待してその結果をさらにLDAで次元削減を実施します。 手順は以下になります。
- 429冊の30579件のレビューに対して形態素解析及びTFIDFを実施、30579x8050の行列を生成
- 1の出力に対しLDAで特徴量の数を20に次元削減し30579x20の行列を生成
- 2の出力を各書籍に対して平均値でまとめ、429x20の行列を生成
- 3の出力にkmeansを用い429冊の書籍を10クラスに分類
クラスタリング結果をt-SNEで2次元マッピングした結果は以下のようになりました。

クラス毎に結構きれいに別れているように見えますが、 潜在表現は本来境界がきれいにみえないのが普通だと思いますので、これはLDAを事前に使っているためですね。 実際LDAをかけずにTFIDFの出力をそのままt-sneにかけるとほとんどクラスによる偏りはみられなくなりました。
各クラスに含まれる書籍上位20件は以下のようになりました。 上の図の左下に位置しているクラス0と3にビジネス書、その他に小説が多く含まれる結果となりました。 ビジネス書や小説の中のクラス毎の解釈は私の目だと少し難しいと感じました。
| クラス | 書籍名 |
|---|---|
| 0 | 世界一やさしい「やりたいこと」の見つけ方 人生のモヤモヤから解放される自己理解メソッド, あやうく一生懸命生きるところだった, 「育ちがいい人」だけが知っていること, 独学大全 絶対に「学ぶこと」をあきらめたくない人のための55の技法, 2020年6月30日にまたここで会おう 瀧本哲史伝説の東大講義 (星海社新書), なぜ僕らは働くのか-君が幸せになるために考えてほしい大切なこと, 会計クイズを解くだけで財務3表がわかる 世界一楽しい決算書の読み方, 言語化力 言葉にできれば人生は変わる, 話すチカラ, 時間をもっと大切にするための小さいノート活用術, 10代から知っておきたい あなたを閉じこめる「ずるい言葉」, みずほ銀行システム統合、苦闘の19年史 史上最大のITプロジェクト「3度目の正直」, コロナの時代の僕ら, コピーライターじゃなくても知っておきたい 心をつかむ超言葉術, エンド・オブ・ライフ, 面白い! を生み出す妄想術 だから僕は、ググらない。, 死にたいけどトッポッキは食べたい, 1%の努力, 宇宙兄弟とFFS理論が教えてくれる あなたの知らないあなたの強み【自己診断ID付き】, スペースキーで見た目を整えるのはやめなさい ~8割の社会人が見落とす資料作成のキホン |
| 1 | 夜明けのすべて, 明け方の若者たち, わたしの美しい庭, ザリガニの鳴くところ, なんで僕に聞くんだろう。, 人は、なぜ他人を許せないのか?, 御社のチャラ男, 首里の馬, 私をくいとめて (朝日文庫), 「具体⇄抽象」トレーニング 思考力が飛躍的にアップする29問 (PHPビジネス新書), これからの男の子たちへ :「男らしさ」から自由になるためのレッスン, パチンコ 上, 愛されなくても別に, 絶対に挫折しない日本史 (新潮新書), 推し、燃ゆ, ゲームの王国 上 (ハヤカワ文庫JA), 帝都地下迷宮, 美しい距離 (文春文庫), ゲームの王国 下 (ハヤカワ文庫JA), 夜の向こうの蛹たち |
| 2 | 一人称単数, イマジン?, まずはこれ食べて, アンマーとぼくら (講談社文庫), まだ温かい鍋を抱いておやすみ, 背高泡立草, トラペジウム (角川文庫), 奈落, ミッドナイトスワン (文春文庫), 口福のレシピ, 希望のゆくえ, 二百十番館にようこそ, お勝手のあん (ハルキ文庫 し) |
| 3 | シン・ニホン AI×データ時代における日本の再生と人材育成 (NewsPicksパブリッシング), 科学的な適職 4021の研究データが導き出す、最高の職業の選び方, 本当の自由を手に入れる お金の大学, 精神科医が教える ストレスフリー超大全 ―― 人生のあらゆる「悩み・不安・疲れ」をなくすためのリスト, Think Smart 間違った思い込みを避けて、賢く生き抜くための思考法, (182)フィンランド人はなぜ午後4時に仕事が終わるのか (ポプラ新書), 父が娘に伝える自由に生きるための30の投資の教え, ワイルドサイドをほっつき歩け --ハマータウンのおっさんたち, 世界標準の経営理論, 遅いインターネット(NewsPicks Book), 文系AI人材になる: 統計・プログラム知識は不要, ビジネスエリートになるための 教養としての投資, ブルシット・ジョブ――クソどうでもいい仕事の理論, FULL POWER 科学が証明した自分を変える最強戦略, これからの会社員の教科書 社内外のあらゆる人から今すぐ評価されるプロの仕事マインド71, 本を読む人だけが手にするもの (ちくま文庫), おうち性教育はじめます 一番やさしい!防犯・SEX・命の伝え方 (MF comic essay), 「考える技術」と「地頭力」がいっきに身につく 東大思考, 雑談の一流、二流、三流 (アスカビジネス), 世界「倒産」図鑑 波乱万丈25社でわかる失敗の理由 |
| 4 | そして、バトンは渡された (文春文庫), 星の子 (朝日文庫), 透明な夜の香り, サキの忘れ物, 魔女たちは眠りを守る, 純喫茶パオーン, ビジネス教養 地政学 (サクッとわかるビジネス教養), 世界観をつくる 「感性×知性」の仕事術, ヒポクラテスの試練, 草花たちの静かな誓い (集英社文庫), 本を売る技術, あの本は読まれているか, 本屋、はじめました 増補版 (ちくま文庫), AIとカラー化した写真でよみがえる戦前・戦争 (光文社新書), 縄紋 |
| 5 | BUTTER (新潮文庫 ゆ 14-3), カケラ, 半沢直樹 アルルカンと道化師, ゴーストハント1 旧校舎怪談 (角川文庫), 赤ずきん、旅の途中で死体と出会う。, 水を縫う, 【2020年・第18回「このミステリーがすごい! 大賞」大賞受賞作】紙鑑定士の事件ファイル 模型の家の殺人 (『このミス』大賞シリーズ), この本を盗む者は, 世界は贈与でできている――資本主義の「すきま」を埋める倫理学 (NewsPicksパブリッシング), ゴーストハント2 人形の檻 (角川文庫), 鹿の王 水底の橋 (角川文庫), ボクはやっと認知症のことがわかった 自らも認知症になった専門医が、日本人に伝えたい遺言, 神話の密室 天久鷹央の事件カルテ (新潮文庫), 村上T 僕の愛したTシャツたち (Popeye books), 始まりの木, スマホを落としただけなのに 戦慄するメガロポリス (宝島社文庫 『このミス』大賞シリーズ), マトリ 厚労省麻薬取締官 (新潮新書), 涼宮ハルヒの直観 (角川スニーカー文庫), 雨の中の涙のように |
| 6 | たゆたえども沈まず (幻冬舎文庫), ホワイトラビット (新潮文庫), クスノキの番人, 少年と犬, マスカレード・ナイト (集英社文庫), 君が夏を走らせる (新潮文庫), 十字架のカルテ, 犯人のいない殺人の夜 新装版 (光文社文庫), 東京、はじまる, ネメシスの使者 (文春文庫), 夜がどれほど暗くても, 僕の神さま, リメンバー (幻冬舎文庫), 旅のつばくろ, あの日、君は何をした (小学館文庫), 隣はシリアルキラー, おもかげ (講談社文庫) |
| 7 | 四畳半タイムマシンブルース, 発注いただきました!, ビブリア古書堂の事件手帖II ~扉子と空白の時~ (メディアワークス文庫), 息吹, 三体Ⅱ 黒暗森林 上, 三体II 黒暗森林 下, きたきた捕物帖, 超・殺人事件 (角川文庫), 暴虎の牙, その裁きは死 (創元推理文庫), ブラック・ショーマンと名もなき町の殺人, 風と共にゆとりぬ (文春文庫), これは経費で落ちません! 7 ~ 経理部の森若さん ~ (集英社オレンジ文庫), 凶犬の眼 (角川文庫), 不穏な眠り (文春文庫), Another 2001, 我々は、みな孤独である, 罪人の選択, 掟上今日子の設計図, 歌舞伎座の怪紳士 (文芸書) |
| 8 | 逆ソクラテス, AX アックス (角川文庫), 「自分だけの答え」が見つかる 13歳からのアート思考, 出会い系サイトで70人と実際に会ってその人に合いそうな本をすすめまくった1年間のこと (河出文庫), ファーストラヴ (文春文庫), 青くて痛くて脆い (角川文庫), 阿佐ヶ谷姉妹ののほほんふたり暮らし (幻冬舎文庫), 20代で得た知見, 猫を棄てる 父親について語るとき, 素敵な日本人 (光文社文庫), お探し物は図書室まで, 表参道のセレブ犬とカバーニャ要塞の野良犬 (文春文庫 わ 25-1), 満月珈琲店の星詠み (文春文庫), 破局, わたしたちは銀のフォークと薬を手にして (幻冬舎文庫), めんどくさがりなきみのための文章教室, 水曜日が消えた (講談社タイガ), 出会いなおし (文春文庫), デトロイト美術館の奇跡 (新潮文庫), 〈あの絵〉のまえで |
| 9 | 夢をかなえるゾウ1, 夢をかなえるゾウ4 ガネーシャと死神, 滅びの前のシャングリラ (単行本), 巴里マカロンの謎 (創元推理文庫), 夢をかなえるゾウ2 ガネーシャと貧乏神, ドミノin上海, 夢をかなえるゾウ3 ブラックガネーシャの教え, 雲を紡ぐ, 52ヘルツのクジラたち (単行本), スキマワラシ, 自転しながら公転する, ハグとナガラ (文春文庫 は 40-5), 逃亡者, この気持ちもいつか忘れる CD付・先行限定版, ハイパーハードボイルドグルメリポート, ([ほ]4-5)活版印刷三日月堂 空色の冊子 (ポプラ文庫), ([ほ]4-6)活版印刷三日月堂 小さな折り紙 (ポプラ文庫), たおやかに輪をえがいて (単行本), 凪に溺れる, 本性 (角川文庫) |
2.Sentence-BERT+kmeans
1のTFIDFを用いたやり方は単語の出現頻度が判定基準になっており、前後関係等の文脈を考慮できていません。 そこで文脈を読むことに定評があるBERTを使用してみます。 調査したところ最終出力ではなく中間層のベクトル表現を用いるのは一般的なBERTはあまり得意ではなく、Sentence-BERTというものが適しているようです。 下記の記事で日本語の学習済みモデルを作成している方がいたので、この学習済みモデルをそのまま使用し書籍のベクトル化とクラスタリングを行いました。
手順は以下のようになります。
- 429冊の30579件のレビューをSentence-BERTの学習済みモデルを用いてベクトル化、30579x768の行列を生成
- 1の出力を各書籍に対して平均値でまとめ、429x768の行列を生成
- 2の出力にkmeansを用い429冊の書籍を10クラスに分類
t-SNEで2次元マッピングした図は以下のようになりました。

各クラスに含まれる書籍上位20件は以下のようになりました。 ビジネス書が左上の領域にあたるのですが、クラス0が自己啓発、クラス4が教養、クラス5がお金、クラス6が書籍、クラス8がITと人の目でわかる粒度で分離ができています。 小説についてはTFIDFの時と同じくクラス毎の解釈が難しいですが、クラス7は明確に食に関するものになっていました。
| クラス | 書籍名 |
|---|---|
| 0 | 「自分だけの答え」が見つかる 13歳からのアート思考, 夢をかなえるゾウ1, 世界一やさしい「やりたいこと」の見つけ方 人生のモヤモヤから解放される自己理解メソッド, あやうく一生懸命生きるところだった, 「育ちがいい人」だけが知っていること, 独学大全 絶対に「学ぶこと」をあきらめたくない人のための55の技法, 2020年6月30日にまたここで会おう 瀧本哲史伝説の東大講義 (星海社新書), なぜ僕らは働くのか-君が幸せになるために考えてほしい大切なこと, 精神科医が教える ストレスフリー超大全 ―― 人生のあらゆる「悩み・不安・疲れ」をなくすためのリスト, 20代で得た知見 |
| 1 | 逆ソクラテス, 青くて痛くて脆い (角川文庫), カケラ, 猫を棄てる 父親について語るとき, 破局, ワイルドサイドをほっつき歩け --ハマータウンのおっさんたち, 丸の内魔法少女ミラクリーナ, 女帝 小池百合子, 御社のチャラ男, 首里の馬 |
| 2 | ホワイトラビット (新潮文庫), 四畳半タイムマシンブルース, マスカレード・ナイト (集英社文庫), 半沢直樹 アルルカンと道化師, 息吹, 水曜日が消えた (講談社タイガ), 三体Ⅱ 黒暗森林 上, ドミノin上海, 三体II 黒暗森林 下, スキマワラシ |
| 3 | たゆたえども沈まず (幻冬舎文庫), 一人称単数, 少年と犬, イマジン?, 素敵な日本人 (光文社文庫), 表参道のセレブ犬とカバーニャ要塞の野良犬 (文春文庫 わ 25-1), 透明な夜の香り, 発注いただきました!, ビブリア古書堂の事件手帖II ~扉子と空白の時~ (メディアワークス文庫), 夢をかなえるゾウ2 ガネーシャと貧乏神 |
| 4 | コロナの時代の僕ら, 遅いインターネット(NewsPicks Book), R帝国 (中公文庫), 空気を読む脳 (講談社+α新書), 人は、なぜ他人を許せないのか?, ブルシット・ジョブ――クソどうでもいい仕事の理論, カエルの楽園2020 (新潮文庫), サル化する世界, 世界「倒産」図鑑 波乱万丈25社でわかる失敗の理由, 時間はどこから来て、なぜ流れるのか? 最新物理学が解く時空・宇宙・意識の「謎」 (ブルーバックス) |
| 5 | 会計クイズを解くだけで財務3表がわかる 世界一楽しい決算書の読み方, 本当の自由を手に入れる お金の大学, 父が娘に伝える自由に生きるための30の投資の教え, ビジネスエリートになるための 教養としての投資, 世界は贈与でできている――資本主義の「すきま」を埋める倫理学 (NewsPicksパブリッシング), すみません、金利ってなんですか?, FIRE 最強の早期リタイア術 最速でお金から自由になれる究極メソッド, 99%の人が気づいていないお金の正体, 現代経済学の直観的方法, お金の真理 (単行本) |
| 6 | 出会い系サイトで70人と実際に会ってその人に合いそうな本をすすめまくった1年間のこと (河出文庫), お探し物は図書室まで, めんどくさがりなきみのための文章教室, わたしが知らないスゴ本は、 きっとあなたが読んでいる, 本を読む人だけが手にするもの (ちくま文庫), 読書嫌いのための図書室案内 (ハヤカワ文庫JA), 戦略読書 〔増補版〕 (日経ビジネス人文庫), NHK出版 学びのきほん 「読む」って、どんなこと? (教養・文化シリーズ NHK出版学びのきほん), 頭がいい人の読書術, (読んだふりしたけど)ぶっちゃけよく分からん、あの名作小説を面白く読む方法 |
| 7 | BUTTER (新潮文庫 ゆ 14-3), 阿佐ヶ谷姉妹ののほほんふたり暮らし (幻冬舎文庫), 巴里マカロンの謎 (創元推理文庫), 満月珈琲店の星詠み (文春文庫), まずはこれ食べて, アンと愛情, 純喫茶パオーン, マカロンはマカロン (創元推理文庫), 注文の多い料理小説集 (文春文庫), まだ温かい鍋を抱いておやすみ |
| 8 | シン・ニホン AI×データ時代における日本の再生と人材育成 (NewsPicksパブリッシング), 科学的な適職 4021の研究データが導き出す、最高の職業の選び方, (182)フィンランド人はなぜ午後4時に仕事が終わるのか (ポプラ新書), みずほ銀行システム統合、苦闘の19年史 史上最大のITプロジェクト「3度目の正直」, 世界標準の経営理論, 文系AI人材になる: 統計・プログラム知識は不要, アフターデジタル2 UXと自由, FULL POWER 科学が証明した自分を変える最強戦略, 異端のすすめ 強みを武器にする生き方 (SB新書), D2C 「世界観」と「テクノロジー」で勝つブランド戦略 (NewsPicksパブリッシング) |
| 9 | AX アックス (角川文庫), クスノキの番人, そして、バトンは渡された (文春文庫), 星の子 (朝日文庫), ファーストラヴ (文春文庫), 夜明けのすべて, 明け方の若者たち, わたしの美しい庭, 夢をかなえるゾウ4 ガネーシャと死神, 滅びの前のシャングリラ (単行本) |
まとめ
TFIDF+LDAとSentence-BERTの2通りの潜在表現の作成方法を用いてレビューを用いて書籍のクラスタリングを行いました。 小説については評価が難しいですが、ビジネス書に関してはSentence-BERTの方が人間が識別しやすい結果が得られたと思います。
レビューは本の内容をそのまま反映しているわけではなく、読んだ人自身がもつフィルタを通した出力であるため、 比較的メッセージが明確なビジネス書だとジャンル分けがある程度できますが、 人によって印象に残る場面や感じ方に幅がある小説は出力結果が安定しないのではないかと感じました。
使用したコードは以下になります。
読書記録(2020年12月,2021年1月)
あなたの人生の科学
誕生・成長・出会い (ハヤカワ文庫NF)")
あなたの人生の科学(上)誕生・成長・出会い (ハヤカワ文庫NF)
- 作者:デイヴィッド・ブルックス
- 発売日: 2015/11/05
- メディア: 文庫
結婚・仕事・旅立ち (ハヤカワ文庫NF)")
あなたの人生の科学(下)結婚・仕事・旅立ち (ハヤカワ文庫NF)
- 作者:デイヴィッド・ブルックス
- 発売日: 2015/11/05
- メディア: 文庫
二人の主人公の一生を例として、物語形式で仕事や結婚などの各エピソードにおいて なぜその人はそのような行動をとるのかを、特に無意識の部分に焦点を当てて解説を行なっている。 参考文献も多く引用してあり認知科学や心理学等使用されている知識は多いが、ストーリー形式だったことで内容が理解しやすかった。他者と協調できる人の遺伝子が残りやすいことを考えると、人はやっぱり社会から逃れることはできなのかなあと思うなどした。
ワークマンは 商品を変えずに売り方を変えただけで なぜ2倍売れたのか

データ分析業界でたまに話題になるワークマンについての本。 データは重視するがいわゆるAIと呼ばれる高度なものは使用しないという部分が気になっていたが、ブラックボックス的な物を使用すると社員が考えなくということで納得がいった。正直若干名のスーパープレイヤーがいるよりこういう方針の方が事業的には安定する気がする。戦略立案から店舗オペレーションまでの仕組みがうまく考えられているという印象で、取引先やフランチャイズとのやりとりも性善説的であり、派手さはないが無駄な仕事の部分が少なそうだなという印象を受けた。
マンスキー データ分析と意思決定理論

- 作者:チャールズ・マンスキー
- 発売日: 2020/09/30
- メディア: Kindle版
データサイエンティストの育て方

- 作者:史朗, 斉藤
- 発売日: 2020/12/09
- メディア: 単行本
メカニズムデザインで勝つ ミクロ経済学のビジネス活用
")
世界が動いた「決断」の物語 新・人類進化

- 作者:スティーブン・ジョンソン
- 発売日: 2019/03/27
- メディア: Kindle版
勉強の哲学 来たるべきバカのために
/メイキング・オブ・勉強の哲学
")
- 作者:雅也, 千葉
- 発売日: 2020/03/10
- メディア: 文庫
")
タイトルから自己啓発に近い内容かと思って読み始めたが、完全に哲学よりの内容でいい意味で裏切られた。 なぜ勉強をするのかというと、ノリで動いている、つまり無意識で周りに合わせている状況に対してなぜそんなことをしているんだ?というツッコミ(アイロニー)をいれ、さらにそのツッコミに対していやそれはアレと同じでは?というユーモアで思考の領域を広げ、そのままだと際限がないためにどこかで止めるために享楽、つまり自身の特性によってやめ時を決定するという話。
この本における勉強は単に机に向けたものに限定しておらず、現状の事象を分解し、 自身の考えでその事象を再構築するために必要な汎用的な技術というイメージ。
メイキング・オブ・勉強の哲学は勉強の哲学という本の制作自体に関して書かれているが、 勉強の哲学という本自体が本文中で述べられているアイロニ→ユーモアー→享楽による切断を経て作成されていると感じられて理解が深まった。
良い戦略、悪い戦略
")
- 作者:リチャード・P・ルメルト
- 発売日: 2020/04/30
- メディア: Kindle版
歴史上や近代の事例を用いて良い戦略と悪い戦略についての説明がなされている。 一例として紀元前のカルタゴの武将であるハンニバルがローマ軍を破った事例が記載されているが、 ここでは戦略を用いるということが一般的ではない時代において、戦力を分散し撤退前提の囮を用いることで圧倒的な勝利を手にしている。 他の事例についても根源的な考え自体は同じで
- 目標と戦略を取り違えず、具体的な行動に落とすところまで考える
- 自身の経験ではなく客観的に当たり前となるべきことを考える
- 戦略を実際に実行する
ということが良い戦略においては重要となるらしい。
物体検出を用いてジャグリング(3ボールカスケード)の回数をカウントする
はじめに
WFHの気分転換でたまにジャグリングをしていて、これ最近の物体検出技術を使えば回数をカウントする仕組みが割と簡単に作れるのでは?と思ったので試しに動画から3ボールカスケードの回数をカウントする仕組みを作成しました。
実施手順
以下の手順で実施しました。
- 動画からボールの座標をyolov5を用いて抽出
- 抽出した座標を元にカウントロジックを作成
1. yolov5を用いた物体検出
公式にあるyolov5の学習済みデータにはsports ballというラベルが含まれているので、それを用いてボールの位置の検出を行います。 学習済みモデルを使うのであれば公式のチュートリアルに従って git cloneしてsourceのファイルを差し替えるだけでできます。 物体検出後の動画はこんな感じ
人がperson、ボールがsports ballというクラスで検出されていることがわかります。 良く見ると手元に近い位置だと赤いボールはapple、黄色いボールはbananaと誤判定されていたりします。
2. カウントロジック作成
物体検出時に実行するdetect.pyの引数に--save-txtとつけることで下記のようなフレームごとの座標を得ることができます。

ここで得られる5つの列はそれぞれ所属クラス、x軸の中心点、y軸の中心点、幅、高さを示します。また、値は0-1の間に正規化されています。 所属クラス0がperson、32がsports ballにあたります。
参考:https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
このデータを用いて回数をカウントするロジックを考えます。
横軸をフレーム番号、縦軸をy座標としてプロットすると以下のようになりました。
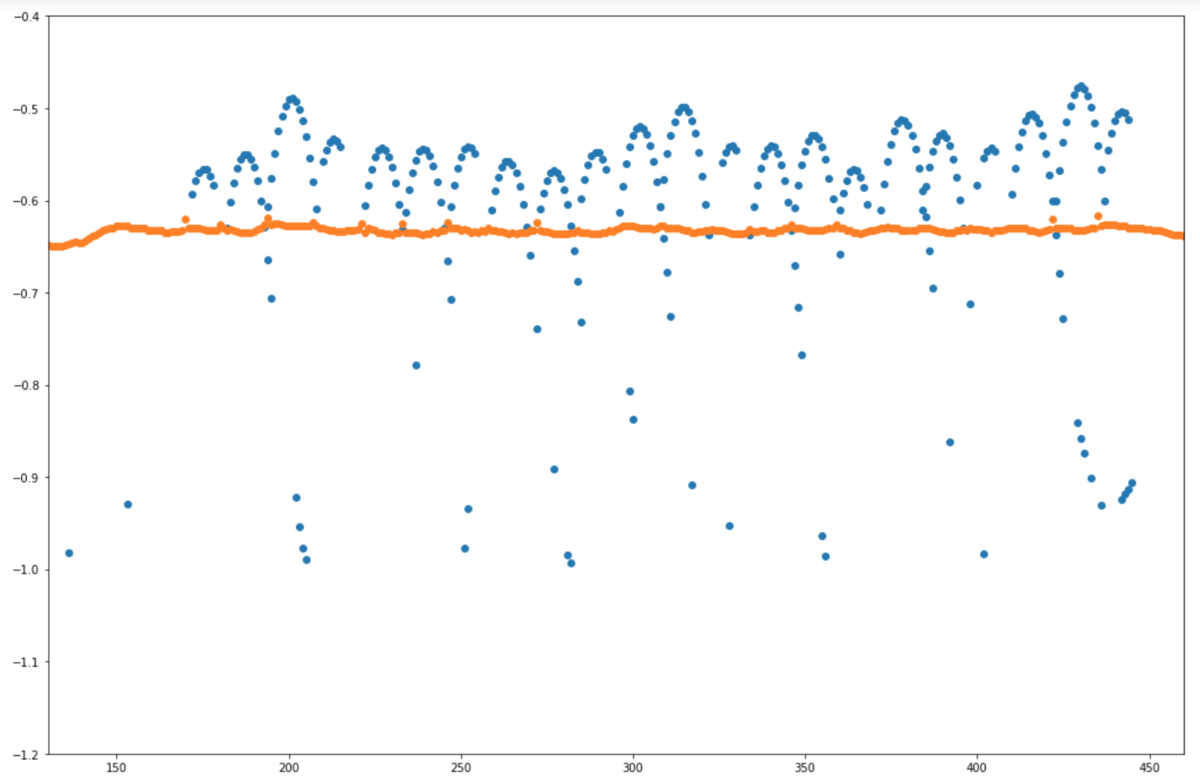
青色のラインがsports ballの中心点、オレンジ色のラインがpersonの上限点になります。 特徴としては、人の体と重なっている部分は検出されないケースが多いですが、頂点近くの放物線は割と正確に検出できていそうです。 そのため今回は最も高い位置にあるボールのy座標が2回連続で上昇、その後2回連続で下降したタイミングを検知したら1回とカウントすることにしてみます。 このロジックを適用すると、回数がカウントされるタイミングは図の赤線部分となりました。
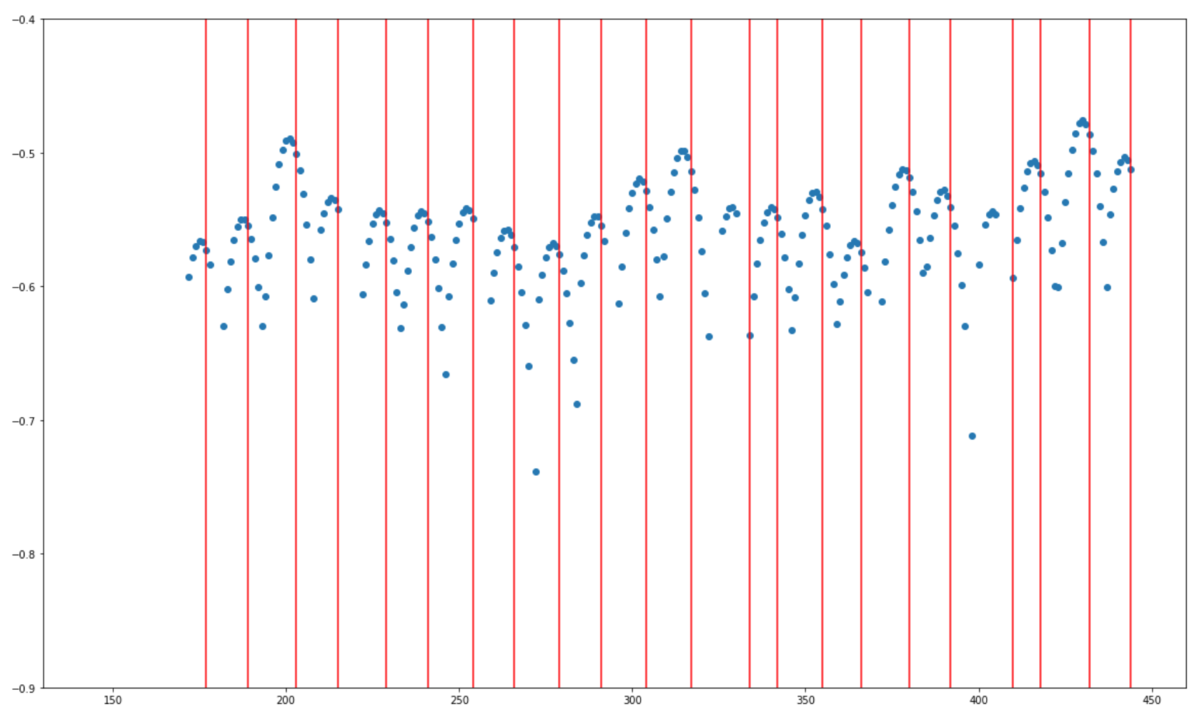
このロジックで良い感じにカウントができていそうです。 確認のためカウントを動画の左下に表示した結果が以下になります。動画は0.25倍速です。
まとめ
yolov5を使って3ボールカスケードの回数をカウントする仕組みを作成しました。 ここではうまくいったサンプルを紹介しましたが、学習済みモデルをそのまま使っているので精度にはやや問題があります。 例えばボールの色によってはうまく物体検出ができません。私は5色のボールを所持していて今回は赤、黄、銀のボールを使用したのですが、青や黒のボールを用いた時は検出がうまく行えませんでした。良く見ると銀のボールも赤や黄に比べると少し検出精度が悪かったりします。 また、体と重なる部分も検出がうまくできていないので、ボールを高くあげないケースではうまくカウントができませんでした。 このあたりを改善したい場合はデータセットを集めてfine tuningする必要がありそうかなと思っています。
使用したコードはこちらになります。
共分散構造分析を試す
はじめに
今回は共分散構造分析を試してみたいと思います。共分散構造分析は手法としては因子分析と回帰分析を組み合わせたようなもので、観測変数から因子分析で潜在変数の導出を、複数の潜在変数同士の関係を回帰分析で行うようなイメージです。例えば国語、数学、理科、社会、英語の点数という観測変数があった場合に、数学、理科には理系能力、国語、社会、英語には文系能力という潜在変数が、さらに理系能力と文系能力に基礎能力という潜在変数があるとした場合にこの構造が数値的に正しいのか、またそれぞれの項目はどのように関連しているかを明らかにするような方法です。
潜在変数間の関係性を示すことができるので、用途としてはマーケティングや心理学など、目的に対して直接的なログデータが取得できず、 何らかの仮定を元に意思決定を行う必要があるケースに使われる場合が多いようです。
参考文献
共分散構造分析を理解するのに役立つ動画
lavaan公式
lavaan日本語チュートリアル
実験
データはkaggleのbig-five-personality-testを使用します。
このデータには心理学でビッグファイブと呼ばれる開放性、誠実性、外向性、協調性、神経症傾向について、各特性10問づつ5段階評価のアンケート結果が含まれます。 アンケート結果が観測変数で、開放性などの各特性が潜在変数と考えられます。同じデータセットに質問にどれくらい時間をかけたかという項目も存在していたので、今回は仮説としてこれらの5つの特性が回答にかける時間に影響を与えていると考え、それぞれの特性がどれくらい時間の項目に影響するかを明らかとします。
データセットの変数は以下になります。
| 変数名 | 説明 |
|---|---|
| EXT(1-10) | 外向性に関する質問項目 |
| EST(1-10) | 誠実性に関する質問項目 |
| AGR(1-10) | 協調性に関する質問項目 |
| CSN(1-10) | 神経症傾向に関する質問項目 |
| OPN(1-10) | 開放性に関する質問項目 |
| introelapse | イントロページでの所要時間 |
| testelapse | 質問回答での所要時間 |
| endelapse | 最終(確認)ページでの所要時間 |
Rのlavaanで実装を行います。
library(lavaan)
library(psych)
library(semTools)
library(semPlot)
library(gplots)
df=read.csv("data-final.csv",sep='\t',na.strings="NULL")
#使用変数
col=c("EXT1","EXT2","EXT3","EXT4","EXT5","EXT6","EXT7","EXT8","EXT9","EXT10",
"EST1","EST2","EST3","EST4","EST5","EST6","EST7","EST8","EST9","EST10",
"AGR1","AGR2","AGR3","AGR4","AGR5","AGR6","AGR7","AGR8","AGR9","AGR10",
"CSN1","CSN2","CSN3","CSN4","CSN5","CSN6","CSN7","CSN8","CSN9","CSN10",
"OPN1","OPN2","OPN3","OPN4","OPN5","OPN6","OPN7","OPN8","OPN9","OPN10",
"testelapse","introelapse","endelapse"
)
xs<-df[,col]
#0,欠損処理
xs[xs == 0] <- NA
xs <- na.omit(xs)
#外れ値処理
xs=xs[xs$testelapse < 1000, ]
xs=xs[xs$introelapse < 1000, ]
xs=xs[xs$endelapse < 1000, ]
#log化
xs[,"testelapse"] <- log(xs$testelapse+1)
xs[,"introelapse"] <- log(xs$introelapse+1)
xs[,"endelapse"] <- log(xs$endelapse+1)
#変更前
model <- '
# measurement model
EXT =~ EXT1+EXT2+EXT3+EXT4+EXT5+EXT6+EXT7+EXT8+EXT9+EXT10
EST =~ EST1+EST2+EST3+EST4+EST5+EST6+EST7+EST8+EST9+EST10
AGR =~ AGR1+AGR2+AGR3+AGR4+AGR5+AGR6+AGR7+AGR8+AGR9+AGR10
CSN =~ CSN1+CSN2+CSN3+CSN4+CSN5+CSN6+CSN7+CSN8+CSN9+CSN10
OPN =~ OPN1+OPN2+OPN3+OPN4+OPN5+OPN6+OPN7+OPN8+OPN9+OPN10
ELP =~ testelapse+introelapse+endelapse
# regressions
ELP ~ EXT+EST+AGR+CSN+OPN
'
fit <- sem(model, data=xs)
summary(fit, fit.measures=TRUE, standardized=TRUE)
前処理について、データセットのサンプルサイズが十分大きいので、欠損を含んだ行は削除しています。 時間を示す変数には異常に大きい値が含まれるのでそのサンプルを削除しています。 またロングテールな変数なので、正規分布に近づけるためにlog化しています。
共分散構造分析では確認すべき指標は結構多いのですが、このモデルでは適合度を示すCFIが0.748と低めでした。 CFIは0.95以上が良適合といわれており、モデルの信頼性を考えるなら0.9以上は欲しいです。
信頼性のないモデルを用いて結果の議論はできないので、CFIの向上を検討します。 使用したモデルだと使用する質問項目が多すぎるかなと思ったので、潜在変数に対してパス値が小さかった項目をカットして各特性に対して使用する質問を2~5問に限定して再度計算を回します。
変更後のモデル
model <- '
# measurement model
EXT =~ EXT2+EXT4+EXT5+EXT7+EXT10
EST =~ EST6+EST7+EST8
AGR =~ AGR4+AGR5+AGR7+AGR9
CSN =~ CSN1+CSN5
OPN =~ OPN5+OPN10
ELP =~ testelapse+introelapse+endelapse
# regressions
ELP ~ EXT+EST+AGR+CSN+OPN
'
この結果、CFIは0.930と良適合まではいきませんが、許容できる数値に収まりました。他の数値についても問題ないレベルでした。 このモデルによるパス図は以下のようになりました。

結果として、各特性(EXT,EST,AGR,CSN,OPN)から時間特性(ELP)へのパス係数はどれも0.1以下と小さい値となり、それほど影響はしていないという結果になりました。 (データセットの制約の問題であまり面白い仮定を置けなかったので仕方ない…。)
まとめ
共分散構造分析はA→B、B→CだからA→Cみたいな論理展開に対して、A→Bは0.6、B→Cは0.7のように数値的に仮説検証ができる部分は面白いと思いました。また結果のわかりやすさに反して信頼性のあるパス図を作るには適切な仮説検証とモデルの試行錯誤が必要であり、実行時に必要な知識や労力は結構かかる方法だと感じました。
使用したコードはこちら
読書記録(2020年10,11月)
超予測力 不確実な時代の先を読む10カ条
")
- 作者:フィリップ E テトロック,ダン ガードナー
- 発売日: 2016/10/31
- メディア: Kindle版
面白かった。大規模な予測プロジェクトの結果を元にどのような性質の人が予測力が高かったかを示している。予測の正確性が高い人は、問題を細分化する、他者の批判的意見を歓迎する、客観的な視点から考える、等の能力を所有する人が多いらしい。高い予測力を持つ人が行なっていることは自分の下した判断について常に粗を探し続けるのと同義なので、本文中にも書かれていたが予測力は幸福さとは相関がとれなさそうという事実も興味深い。
コンサル一年目が学ぶこと

内容としては一定以上仕事に興味がある会社員は知っている内容かなという感じだったので、歴が若い人の教材としては良いかなと思った。(知っていることと実行することは別なのでコンサル以外でここまでやる人はあまりいないかなという気もする。)
武器としての交渉思考
")
人と関わる限りは交渉というものが発生するわけだけど、 所有するカードの強さは人によって異なるので、得たいもののために何を譲歩すべきか、 というポイントを探すゲームであり、より適した解を得るには相手のことを知ることが必要なんだよな、と改めて思った。
最も賢い億万長者〈上〉――数学者シモンズはいかにしてマーケットを解読したか

最も賢い億万長者〈上〉――数学者シモンズはいかにしてマーケットを解読したか
- 作者:グレゴリー・ザッカーマン
- 発売日: 2020/09/30
- メディア: Kindle版
あまりはまらなかったので下巻は未読。 物語的なのに、洋書特有の特に背景や感情説明なく物事が高速で進んでいくのが合わなかった。
PRINCIPLES(プリンシプルズ) 人生と仕事の原則
 人生と仕事の原則 (日本経済新聞出版)")
長い、けど著者はおそらくこういうことをずっと考えていて、まとめてもこの分量だったのかなと感じた。 仕事に関する本は多くあって、それらにはある程度同じことが書かれているけど、この本で特徴的だったのは組織としての仕組みに着目している点だと思った。 エンジニア的な視点で自分を含めた組織をマシンとして考え、うまくいってない部分やボトルネックになる部分を 改善していくという発想は理解しやすかった。(人は機械ほど明確なエラーを出してくれるわけではないが…。) 個人の力はもちろん必要なわけだけどそれを活かすには、失敗を隠さない、とか物事に対してフィードバックを必ずかける、 評価をきっちりする、等の仕組みの部分が必要なんだなと思った。
独学大全――絶対に「学ぶこと」をあきらめたくない人のための55の技法

見た目はかなりごついが絵や大見出しが多いため、読むのは思ったほど大変ではなかった。 内容としては、独学にあたって、なぜ(why)、何を(what)、どのように(how)学ぶのか、ということが別れて記述されている点が良かった。 読んでいて思ったのが人に実施することを宣言すると挫折率が下がる、とか逆説的な目標を立てるとか、 自身が人間であることを認識し、人間がどのような性質をもっているかを認識することが学習するのに寄与するという印象をうけた。 ということでそろそろ途中読みになっている利己的な遺伝子を再読しないとな…。
MaaS モビリティ革命の先にある全産業のゲームチェンジ

MaaSに関して、その出自とコンセプトから、影響がある業界、具体的な各社対応、今後の展望まで網羅的に記載がなされており、 全体像の理解に役立った。一番進んでいるwhim(ヘルシンキ)ではMaaSの5段階レベルのうち4段階目である移動サービスの統合・サービス定額化まで実現されているわけだけど、ここは元々マイカー需要を減らして公共交通機関をより使用してもらうようにすることが目的だったので、日本での導入にはまた違った形が必要らしい。
Q-learningで倒立振子を振り回す
はじめに
最近kaggleでも強化学習系のお題が増えてきたように思うので(実際に解法に強化学習が使用されているかは別として)、 手をつけていなかった強化学習について、本を読みながら試してみたことを書きます。
参考資料
実施したこと
openAIのgymのcart-poleの環境を使って強化学習の一種であるQ-learningを実行します。 本来これは下の図のような棒を乗せた車を左右にうまく動かして棒を倒立している状態に保つというのがタスクになりますが、 普通にやっても面白くないので今回は画面外に出ないように棒の角速度が最大になるような動作を強化学習により実施することを目的とします。

手法については、TD法のQ-learningを使います。Q-learningはQテーブルという状態ごとにどうactionをとるべきかというテーブルを作成することに強化学習を実現する方法であり、式としては以下のような形でステップ毎に行動価値関数であるQテーブルを更新していくような形となります。

ここで、が状態、
が行動、
は学習率、
は割引率を示し、
での状態を元に、
の時のQテーブルをパラメータに従い更新します。
コードは基本的には参考文献のものを参考にしているのでここでは割愛し、 今回の問題設定に伴い修正を行った点についてのみ記載します。
一応実装全文はこちらです。
今回は棒の速度をとにかくあげたいので、報酬の部分はこのような形としています。
if abs(state[0]) > 2.4: # カートが範囲外 reward = -1000 else: reward = state[3] #角速度をそのまま報酬に
state[0]はカートに位置、state[3]は棒の角速度で、カートが画面外に出るような場合は大きなマイナス報酬を与え、あとは角速度 をそのまま報酬として与えています。角速度のレンジは設定では無制限となっていますが、実験上では20を超える数値が出ることはほとんどありませんでした。
またcartpoleのdefaultの設定だと角度が12 * 2 * math.pi / 360を越えると棒が倒れたと判定されて終了フラグであるdoneが1となってしまい動画の保存が失敗するので、それを無制限に変更し、最大ステップ数も変更します(defaultは200)。 また1000episode毎に動画を保存するために下記の設定を入れます。
env = gym.make('CartPole-v0') env.env.theta_threshold_radians = float('inf') env._max_episode_steps = 1000 env = wrappers.Monitor(env, directory='movie', force=True, video_callable=( lambda ep: ep % 1000 == 0)) # 1000epsodeごとに動画を保存
結果
実験を行い、収束を確認するために100試行平均の最高角速度の推移を確認すると、おおよそ4000試行程度で性能が頭打ちになりました。平均しているのは試行ごとの振れ幅が大きいためです。

4000試行後のサンプルをいくつか見てみます。
- 4000試行目

最初あまりうまくいっていないか?と思わせて途中から覚醒するパターン。
- 5000試行目

すぐに画面外に出るという典型的なうまくいっていないサンプル。
- 6000試行目

悪くはないが4000試行の例に比べると速度が物足りない。
所感
倒立振子で角速度が最大になることを目的に強化学習の一種であるQ-learningを行いました。結果としては、指標的には学習自体はそれなりにうまくいき、良い感じのサンプルも得られたのですが、サンプル毎のブレ幅が大きく安定した結果を得ることはできませんでした。理想としては画面中央で左右に小刻みに動いて一定の速度を維持し続けて欲しかったのですが、なかなか難しいなという印象です。 ここで記載した結果は一例であり、実際は探索と活用の割合、報酬関数の数値設定、学習率、Qテーブルの離散化数などの多数のパラメータを変更しながら実験を行ったわけですが、パラメータサーチにそれなりに時間もかかりますし、より高度なDQNを使おうとするとこの時間が更に跳ね上がるので、NNの層作りに近い難しさを感じています。