SIRモデルとネットワークモデルを用いて身近にコロナ感染経験者が存在する確率をシミュレーションする
はじめに
最近は街を見ると人通りがコロナ前に戻っていたりしますが、感染者数自体はそれほど減っていないのでこのような状況となっているのは、身近にコロナの感染経験者がいないことも原因の一つであるのではないかという仮説があります。人は身近に起こったことや直近で起こったことを過大評価する反面、逆のケースには鈍感であるという傾向があります。そのため身近に感染経験者がいない場合、報道や注意喚起に従う可能性が低下する可能性があるのではないかと考えています。
人と人とのつながりは仕事やサークル、地域等の集団があり、それらの集団同士がゆるく繋がっているという性質があります。そのため、感染経験者のいる集団には感染者は多くいるが、そうでない集団では感染経験者が全くいないという状況が発生し、後者の集団では感染者数という数字以上にコロナを身近に感じる可能性が下がるのではないかと考えています。
今回はその検証のためSIRモデルとネットワークモデルを用いたシミュレーションモデルを作成します。
※注意事項:今回の結果は多くの仮説の上に成り立っており、またあまり妥当性の高いモデルをつくれたとはいえないので、結果はあくまで思考実験の一つとして捉えていただけると幸いです。
使用モデルについて
SIRモデルとネットワークモデルについてはwebで詳細なものが簡単に見つかるため、ここでは簡単な説明のみ記述します。 SIRモデル+ネットワーク分析の実施方法についてはこちらの記事を参考にさせていただきました。
SIRモデルについて
感染症のモデルとして有名なものですね。
S(susceptible):未感染者
I(susceptible):感染者
R(susceptible):治癒者および死亡者
というパラメータを設定し、全体(S+I+R)を一定として確率的にS→IおよびI→Rへの遷移が発生するというシンプルなモデルになります。
ネットワークモデルについて
人の社会ネットワークは複雑ネットワークの一種として考えられ、その特徴としては、 知り合い関係を順にたどっていけば比較的簡単に世界中の誰にでも行き着くというスモールワールド性と、 大多数の人は少数の知人しかいないが、一部の人は非常に多くの知人をもつというスケールフリー性があると言われています。
スモールワールドを仮定するモデル構造としては ワッツ・ストロガッツモデル(WSモデル)。 スケールフリー性を仮定するモデル構造としてはバラバシ・アルバートモデル(BAモデル)が挙げられます。
今回は上記2つのモデルにランダムモデルを加えた3つモデルを用いて実験を行います。
動作イメージ
水色のノードが未感染者、橙色が感染者、緑色が治癒者・死亡者とし、 感染率と治癒率を1、ノード数を10とした場合のシミュレーションのイメージを示します。
step0
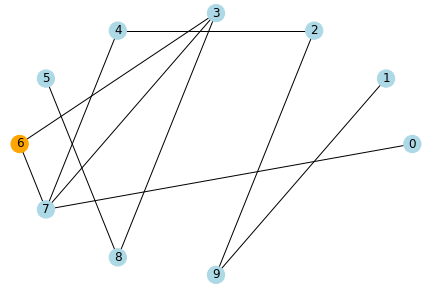
step1
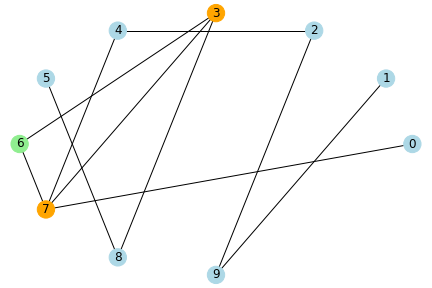
step2

step3
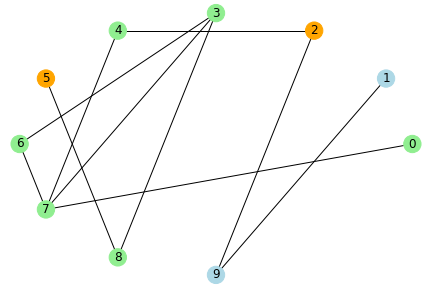
step4
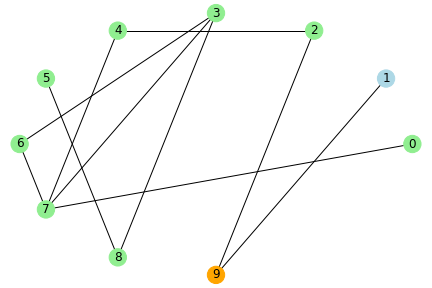
step5
ネットワーク上でつながりのある人に感染が伝わっていき、このパラメータの場合だと、5stepで未感染者はいなくなりました。
実験
シミュレーションのパラメータを現実に近づけます。 本当は日本全国を対象にしてシミュレーションを行いたかったのですが、 計算負荷の問題のため、今回は東京都港区のみを対象として現実に近いモデルを作成することを目指します。
東京都のサイト によると、データの始まりである2020年3月31日時点の陽性判者は39人、2021年6月25日時点では陽性判定者は5633人です。これと港区の人口が24万であるという情報を用います。
モデルのパラメータについて
SIRモデルのパラメータとしては、
感染率:0.007、治癒・死亡率:1/14、初期感染者数:10人
としています。これはできるだけ長い時間をかけて感染者を5000に近づけようと調整したものになります。 (これ以上感染者数を下げると感染者が5000人に届きません。)
このモデルのシミュレーションで1日毎に判定をかけて5000人を超えたタイミングで打ち切り、24万人の対象者それぞれに対し最も近い感染経験者への近さを算出します。
ワッツ・ストロガッツモデルのパラメータとして、一人当たりで繋がりのある人数は20人としています。 また、バラバシ・アルバートモデルのパラメータとして、繋がりのある人数の最小値を6としています。
以下コードになります。
import numpy as np import pandas as pd import networkx as nx import matplotlib.pyplot as plt import ndlib.models.epidemics as ep import ndlib.models.ModelConfig as mc from bokeh.io import output_notebook, show from ndlib.viz.bokeh.DiffusionTrend import DiffusionTrend # ネットワークモデル設定 g = nx.watts_strogatz_graph(240000, 20, 0.1, seed=42) # g=nx.barabasi_albert_graph(240000,6,seed=42) # g = nx.watts_strogatz_graph(240000, 20, 1, seed=42) # random graph model = ep.SIRModel(g, seed=42) # SIRモデル設定 cfg = mc.Configuration() cfg.add_model_parameter('beta', 0.007) # 感染率 cfg.add_model_parameter('gamma', 1/14) # 回復率(2週間) cfg.add_model_parameter("fraction_infected", 10/240000) # 初期感染率 model.set_initial_status(cfg) # SIRシミュレーションを実行、治癒・死亡者が5000を超えたら終了 S_num = [] I_num = [] R_num = [] for i in range(1000): tmp_params = model.iteration() S_num.append(tmp_params["node_count"][0]) I_num.append(tmp_params["node_count"][1]) R_num.append(tmp_params["node_count"][2]) if tmp_params["node_count"][1]+tmp_params["node_count"][2] > 5000: break if i % 10 == 0: print(i) # 感染者および治癒・死亡者のノードリスト作成 inected = [] for i in range(len(model.status)): if model.status[i] > 0: inected.append(i) # 感染者を起点として各ノードへの経路長を計算(最大探索経路長2)。 # 全感染者で実行後の最小値が各ノードから感染者への最小経路長となる。 d = {} for i in range(240000): d[i] = 99 # 各ノードから感染者への最短経路長を集計 cnt = 0 for i in inected: tmp = nx.single_source_shortest_path_length(g, i, cutoff=2) # カットオフの距離まで探索 for k, v in tmp.items(): if d[k] > v: d[k] = v # カウント pd.Series(d.values()).value_counts()
結果はこのようになりました。
| 感染者との近さ | randomモデル | WSモデル | BAモデル |
|---|---|---|---|
| 0 | 5221 | 5056 | 5165 |
| 1 | 78096 | 25022 | 97448 |
| 2 | 156564 | 127952 | 136958 |
| それ以上 | 119 | 81970 | 429 |
感染者との近さ=0の人は感染者自身です。 感染者との近さ=1である身近な人が感染したことのある割合はBAモデル>randomモデル>WSモデルという結果になりました。 今回のBAモデルの構造を見てみると、1000人以上と繋がりのある人が10人以上おり、その人たちが感染を媒介してしまうような動きをしていたのでこのような結果となっているようでした。BAモデルについては少し現実と乖離のあるものになってしまったなと思います。 ランダムモデルとWSモデルを比較すると、WSモデルの方はランダムモデルと比べ、近さが1である人の割合が約1/3となっています。 なので、もし現実の社会構造が今回のようなWSモデルであった場合には、実際の数字よりも身近に感染経験者がいる確率は1/3程度になるといえるのではないでしょうか。
まとめ
SIRモデル+ネットワークモデルを用い、身近な人に感染経験者が存在する確率を算出するためのシミュレーションを行いました。 ネットワークモデルとしてWSモデルを用いた場合に、ランダムモデルと比較すると身近な人が感染経験者である割合は約1/3という結果になりました。 ただ、今回の実験では以下のような現実との乖離が考えられるので、より妥当性の高い結果を出したいのであれば考慮していく必要がありそうです。
- SIRモデルは何も対策を取らない場合にどうなるかを予測するモデルであり、実際の感染者数は予測した数値を元に対策をとった後の数値となるので、実際の陽性者数をSIRモデルで模擬するのは難しい
- 実際のネットワークモデルは集団性を持ち、かつ繋がりのある人数は個人差があるので、WSモデルとBAモデルを混合したような構造になるのではないか
使用したコードは下記になります。